
2024年01月22日,生物信息學專業期刊Briefings In Bioinformatics在線發表了万博英超狼队网官方网
徐書華教授團隊和北京交通大學倪旭敏副教授團隊題為“Reconstructing complex admixture history using a hierarchical model”的研究成果。該項工作提出了一種新方法HierarchyMix,相對於傳統方法通常隻能推斷人群基因交流中兩種祖源的情形,HierarchyMix可重構多至四種祖源的複雜遺傳混合曆史,並應用於我國西北及中亞地區人群的複雜曆史研究。
我國西北及中亞地區位於歐亞大陸中心,涉及多種文化、民族和宗教,對促進歐亞大陸經濟、文化以及遺傳交流起著十分重要的作用。該地區的人群長期受到遷移、隔離以及不同祖源人群混合事件的影響,形成了豐富的遺傳地貌。先前的研究表明,我國西北及中亞地區的混合人群中主要包含西歐、南亞、東亞以及西伯利亞四種祖源,其混合曆史呈現出較為複雜的“混合之混合”模式,即西歐人群與南亞人群發生混合形成一個初始混合人群,東亞人群與西伯利亞人群發生混合形成另一個初始混合人群,之後這兩個初始混合人群進一步發生基因交流,形成當今的我國西北及中亞混合人群。然而,現有的方法和工具均無法對如此複雜的混合模式進行有效的重構和解析。
該項研究首次提出了“層級混合模型(Hierarchical admixture model,HA model)”以描述複雜遺傳混合模式,並開發了HierarchyMix方法對人群複雜混合曆史進行重構和解析。HierarchyMix方法主要考慮兩類混合模型:層級混合模型和次序混合模型(Sequential admixture model,SA model)(圖1)。這兩類模型的不同之處在於層級混合模型為四個祖先人群先兩兩混合分別生成兩個初始混合人群,之後兩個初始混合人群進一步發生基因交流形成近期混合人群,而次序混合模型則為每一個祖源人群依次發生遺傳混合,從而形成最終的混合人群。由於兩類模型中每個祖源群體都隻貢獻了一次主體混合,混合人群基因組中祖源片段長度分布服從單一指數分布,因此無法直接通過祖源片段長度分布模式來區分這兩類模型。幸運的是,團隊研究發現不同的混合模式,混合人群基因組中祖先間跳轉數量分布在不同遺傳混合曆史過程中存在差異(圖2)。
因此,HierarchyMix方法綜合考慮祖源片段長度分布和祖先間跳轉數量分布信息進行混合曆史推斷,其計算框架主要可以分為以下三部分(圖3)。首先,結合混合人群基因組中祖先間跳轉數量分布信息,利用貝葉斯信息準則進行最優混合模型的選擇。其次,在最優混合模型下,結合混合人群基因組中祖源片段長度分布信息,利用極大似然法對混合時間和混合比例進行參數估計。最後,結合以上結果重構混合曆史,輸出適用於該混合人群的最優混合模型及參數。
係統的計算模擬結果表明,HierarchyMix方法在不同混合模式下進行模型選擇以及參數估計均有較高的準確性,且在應對各類數據噪聲時也表現出良好的穩健性。在應用於真實數據分析中,主要以我國西北及中亞地區的兩個典型混合人群新疆維吾爾族人群和哈薩克斯坦人群為例,展示了HierarchyMix方法的實際應用價值。結果表明,新疆維吾爾族人群和哈薩克斯坦人群的混合模式均為層級混合模型,即西歐人群與南亞人群之間發生混合,東亞人群與西伯利亞人群之間發生混合,隨後這兩個形成的初始混合人群之間進一步發生基因交流,最終形成現今的混合人群。這與之前通過更為繁複的分析得到的研究結果保持一致。
總體來講,HierarchyMix方法的提出為重構人類複雜混合曆史提供了新的思路和工具。隨著基因組測序技術的進一步發展,世界範圍內的高質量基因組數據迅速大規模累積,在帶來新的機遇的同時也一定程度上給現有統計方法和算法工具的適用場景提出新的挑戰。無論如何,計算方法的不斷改進有望為深入探究現代人類在宏大時空框架下的分化、融合與適應性進化曆史提供更多可能,並為進一步解析人類起源與演化中更深層次的基礎理論問題提供了新的視角。
北京交通大學畢業生張拾碩士、中國科學院大學畢業生張瑞博士和苑鍇博士為該研究的共同第一作者,狗万外围充值 徐書華教授與北京交通大學倪旭敏副教授為共同通訊作者。此外,北京交通大學在讀研究生楊路、中國科學院大學畢業生劉暢博士和北京交通大學劉玉婷副教授也參與了該項工作的完成。該研究獲得了國家重點研發計劃、國家自然科學基金委、英國皇家學會牛頓基金、北京市自然科學基金等多項基金的資助。
論文鏈接:https://academic.oup.com/bib/article/25/2/bbad540/7584785?login=false
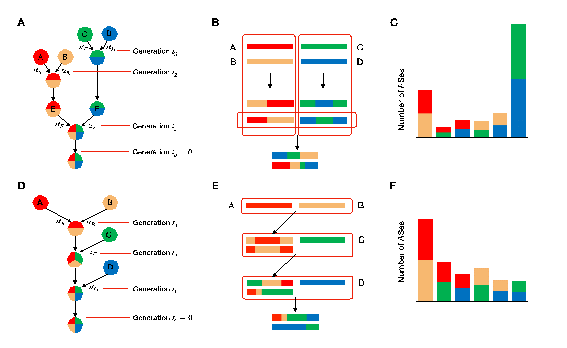
圖 1. 層級混合模型與次序混合模型
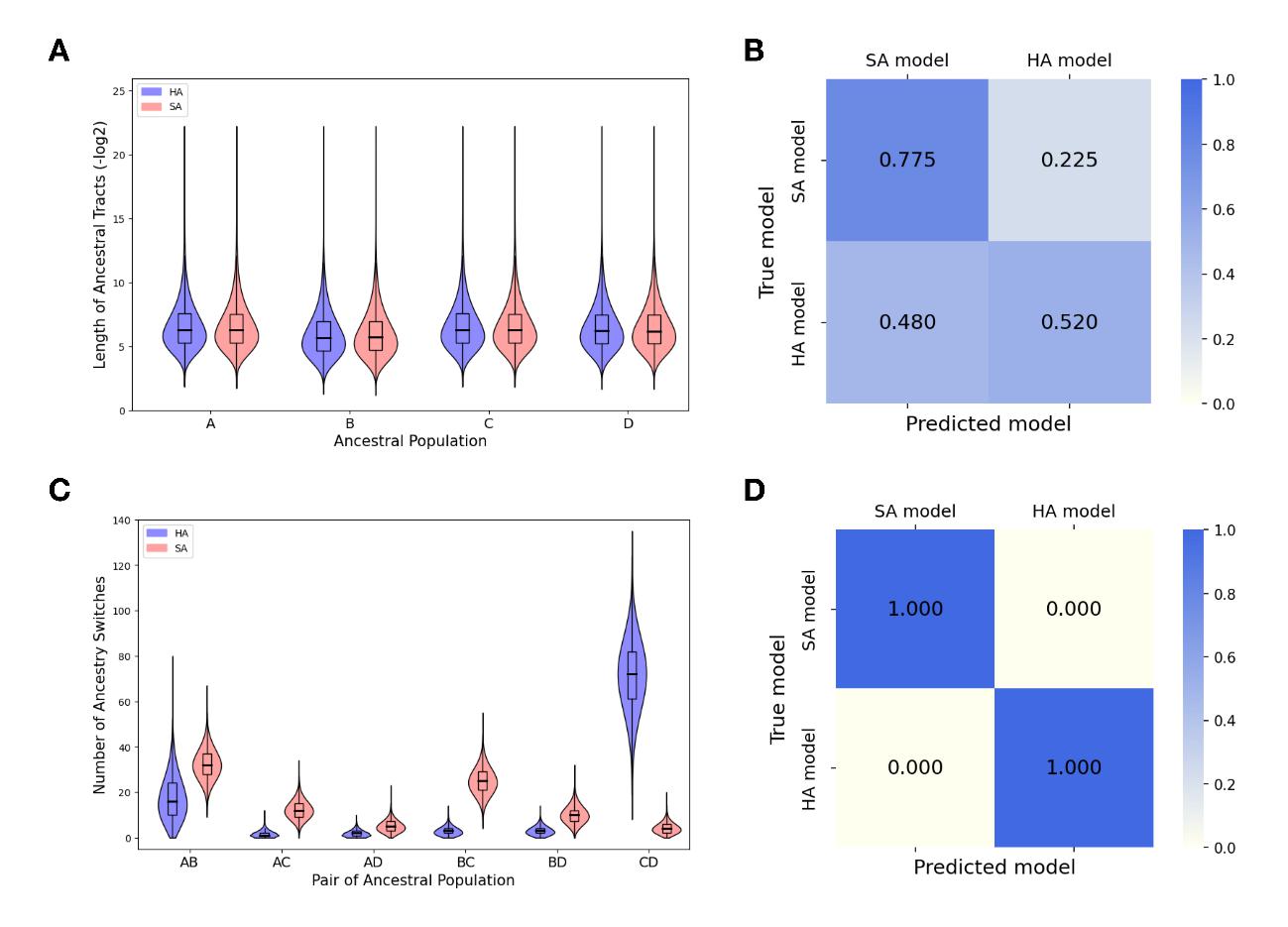
圖 2. 不同模型下祖源片段長度分布和祖先間跳轉數量分布差異及模型選擇

圖 3. HierarchyMix算法流程示意圖